Questa prima lezione del corso di HTML è estremamente teorica, non vedremo neanche una riga di codice, ma vi posso assicurare che questa lezione è estremamente utile per poter comprendere appieno come funziona il browser e di conseguenza come HTML viene mostrato in pagina.
La prima domanda che ci dobbiamo fare quindi non è tanto "Cos'è HTML?", ma come facciamo a vedere le pagine web nel nostro browser.
Cos’è e come funziona il browser
Il browser è quel software che usiamo per navigare il web. Il più utilizzato al mondo è Google Chrome, ma ce ne sono tantissimi altri, come ad esempio Mozilla Firefox, Apple Safari, Microsoft Edge, Brave, Opera e tanti altri ancora.
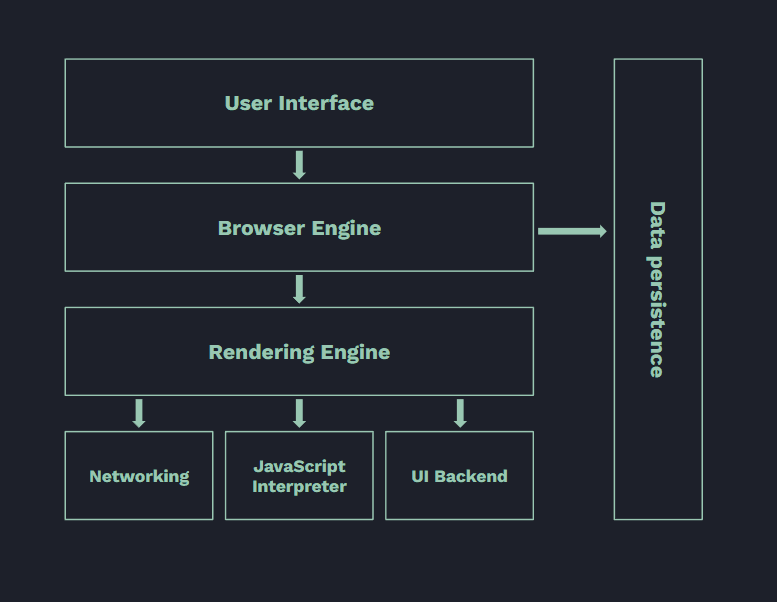
Il browser è un software particolarmente complesso, ma che possiamo semplificare in sette componenti:
- User Interface: ciò che è grafico (barra degli indirizzi, navigazione nella cronologia, tasto home, ecc.) è gestito da questo componente;
- Browser Engine: esegue il marshalling (traduzione delle informazioni) tra il componente di User Interface e il Rendering Engine.
- Rendering Engine: elabora e mostra il contenuto richiesto (ad esempio un documento HTML)
- Networking: gestisce le chiamate alla rete, come le richieste HTTP
- UI Backend: ogni sistema operativo renderizza in maniera differente elementi come bottoni e input, questo perché il componente di UI Backend si interfaccia al sistema operativo per renderizzarli correttamente. Ciò significa che gli utenti Apple li vedranno in maniera differente rispetto agli utenti Windows.
- Javascript Interpreter: analizza ed esegue il codice Javascript. Consideriamo che il linguaggio Javascript non viene interpretato direttamente dal computer, i browser sono dotati di un motore apposito per poterlo interpretare. Quando Google rese open source il suo motore JS nel 2008, il V8, l’anno successivo venne rilasciato Node.js il quale permette di eseguire Javascript al di fuori dal browser rendendolo idoneo anche all’utilizzo server side.
- Data Storage: livello persistente che serve al browser per salvare dei dati in memoria, come cookie, local e session storage.
Il primo passaggio: la richiesta
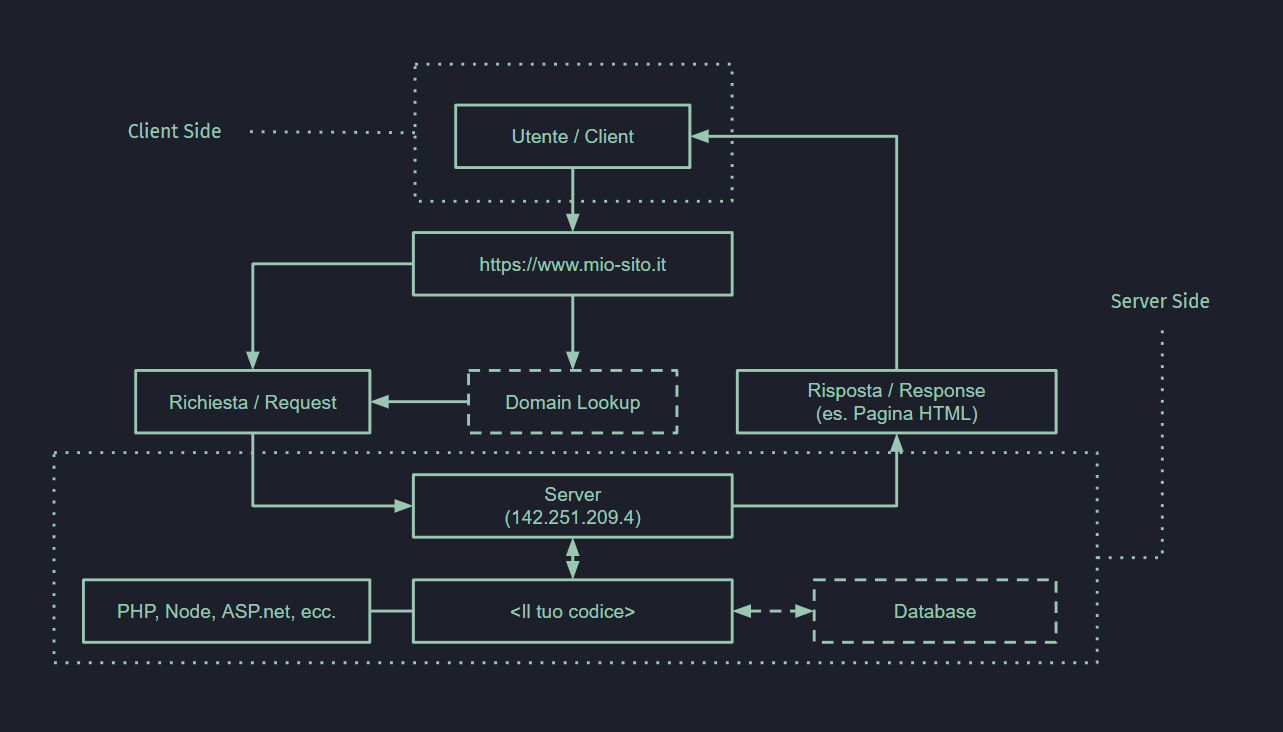
Per arrivare ad impiegare tutti gli elementi del browser dobbiamo innanzitutto fare una richiesta.
Per richiesta si intende a tutti gli effetti una richiesta ad un computer che si trova in qualche parte del mondo. Questo computer si chiama server e sarà il responsabile di fornire una risposta alla nostra richiesta.
La richiesta può essere ad esempio la visualizzazione della homepage di un sito, come quello sulla quale state leggendo questo approfondimento.
Continua dopo il banner

E così vuoi diventare un programmatore, il mio ebook dove do qualche consiglio ha chi si vuole lanciare nella carriera della programmazione. Diciamo che ho raccolto i consigli che avrei voluto sentirmi dire quando ho iniziato.
Scopri cosa contieneSe fosse la prima volta che richiedete questo sito il giro da fare è un pochino più largo e prevede l’interrogazione dei DNS, i quali sono delle gigantesche rubriche telefoniche dove a nome di dominio corrisponde indirizzo IP. L’indirizzo IP è quello del server che ospita il nostro sito.
Se invece il sito fosse stato già visitato in precedenza si accede ad una speciale cache di rete che permette di saltare qualche passaggio, altrimenti essenziale. La richiesta quindi viene instradata e recapitata al server, il quale la elabora e restituisce una risposta. In caso affermativo ci verrà restituito il documento che stavamo cercando accompagnato da un codice 200 (nel caso non ci fosse perché non esiste il codice sarebbe il famoso 404).
Il documento, nel nostro caso supponendo che sia un documento HTML, viene recapitato al browser, il quale eseguirà tutta una serie di passaggi, quali? Scopriamoli.
Il parsing del documento HTML
Quando il server restituisce al client il documento, quest’ultimo viene recuperato dal rendering engine dal livello di networking in chunks da 8KB.
Ogni chunk viene sottoposto a quattro attività principali:
- Encoding
- Pre-parsing
- Tokenization
- Tree construction
Encoding
Il parser la prima cosa che fa con il payload che mano a mano elabora è definire come deve interpretare i bit che riceve. Definire il come non è proprio immediato.
Il decoder deve capire come il documento di testo è stato tradotto in bit per invertire il processo.
Il server dovrebbe fornire qualche indizio come l’header Content-Type.
Se il browser non riesce a stabilire la codifica, cerca di indovinare euristicamente.
La risposta definitiva potrebbe essere fornita da un tag <meta> e se il browser avesse azzardato un'ipotesi prima di arrivare al tag in questione, la scarta in favore del tag.
Oggi si tende ad usare la codifica UTF-8. I motivi sono semplici:
- Supporto totale di UNICODE
- Buona compatibilità con ASCII
- Nei principali browser è la codifica di fallback qualora tutti i passaggi precedenti fallissero.
La codifica in ogni caso potrebbe non andare a buon fine e da cosa si può capire? Beh dal modo in cui vengono mostrati i caratteri a video.
 Fonte: Stackoverflow
Fonte: Stackoverflow
Pre-parsing
Stabilito l’encoding il parser esegue una pre-scansione del contenuto. L’obiettivo è quello di minimizzare la latenza di richiesta e ricezione di risorse addizionali.
Il pre-parser non svolge un’attività di parsing completa. Ad esempio, non bada alle relazioni genitore/figlio dei tag, ma riconosce specifici tag, attributi e URL.
Se dovesse trovare un’immagine, la quale usa l’attributo src per indicare quale sia l’immagine da usare, attraverso il livello di networking viene instradata una nuova richiesta al server per ricevere quanto prima l’immagine in questione. Questo avviene anche per altri elementi come fogli di stile (CSS), script (JavaScript) e altri contenuti multimediali.
Altre direttive che vengono messe in coda sono preload e prefetch di cui parleremo in maniera più approfondita nelle lezioni successive.
Tokenization
La prima parte della vera e propria parsificazione. In sostanza individua i tag di apertura, di chiusura, testo, commenti, ecc.
Per fare ciò il tokenizer ha ottanta stati, i quali sono sostanzialmente caratteri o gruppi di caratteri che l’algoritmo ricerca per trasformare quindi il documento di testo in HTML.
L’esito di questa prima parte di parsificazione è la creazione di questi token, i quali verranno successivamente elaborati dalla seconda parte, che vedremo tra qualche paragrafo.
Tokenizer e parser riescono a gestire qualunque documento di testo e trasformarlo in HTML, anche se il codice non è valido.
Tokenization e pre-parsing possono essere accorpati in un unico step per ottimizzare i tempi.
Tree construction
Il browser ha bisogno di una rappresentazione della pagina web salvata in memoria.
La seconda fase di parsing è l’elaborazione dei token creati dal tokenizer e creare ed inserire gli oggetti nel DOM (Document Object Model) nel modo più appropriato.
Il DOM è organizzato in una struttura dati ad albero ed è qui che prende il nome questo step (tree construction).
La parsificazione di HTML a questo punto si fa complessa per via di tutti i possibili errori che deve intercettare, soprattutto per poter garantire la compatibilità con i codici più vecchi (legacy).
Dopo la creazione del DOM queste regole che cercando di creare un HTML corretto non sono più in azione. Il rendering engine sarà responsabile di gestire eventuali cambi del DOM, anche i più bizzarri.
Piccola nota su JavaScript
JavaScript ha la capacità di modificare il DOM e aggiungere nuovi elementi. Se il parser dovesse trovare del JavaScript, manderà il testo al JavaScript Interpreter (o JavaScript Engine) per l’elaborazione.
Se questo dovesse fare uso dell’API document.write, tutto quello che il browser stava facendo viene messo in pausa, viene attivato un secondo parser che cerca di stabilire le modifiche da apportare. Durante questo processo tutto rimane in pausa finché non termina l’elaborazione.
Termine del parsing
Una volta terminato il parsing, il browser invia un evento chiamato DOMContentLoaded.
Gli eventi sono un sistema del browser per comunicare a JavaScript che sta succedendo qualcosa. Non esiste solo DOMContentLoaded, ma ce ne sono tantissimi altri.
Il ruolo di HTML in tutto questo
HTML è il documento iniziale che avvia tutta la procedura. HTML fornisce la struttura, CSS fornisce l’estetica, mentre JavaScript ci permette di interagire con il DOM e manipolare la pagina.
A questo punto possiamo tornare a porci la vera domanda che ci volevamo porre all’inizio della lezione.
Cos’è HTML?
Partiamo con il chiarire da subito che HTML non è un linguaggio di programmazione.
HTML (Hyper Text Markup Language) è un linguaggio a marcatori, utilizzato per strutturare le pagine web. Deriva dal metalinguaggio SGML (Standard Generalized Markup Language), come XML e SVG. L’evoluzione del linguaggio è seguita dalla WHATWG (Web Hypertext Application Technology Working Group) gruppo fondato da Apple, Mozilla Foundation e Opera Software, alla quale successivamente si unì anche Google.
Ma perché HTML non è un linguaggio di programmazione?
Un computer svolge sostanzialmente tre azioni:
- Legge i dati in memoria,
- esegue una logica condizionale sui dati
- esegue quella stessa logica iterativamente a grande velocità.
Un linguaggio di programmazione deve permettere di svolgere queste tre attività. HTML non fa niente di tutto ciò.
HTML non permette l’uso di logica condizionale, controllo, memorizzazione dei dati e conseguente recupero, cicli o qualsiasi altra cosa che un linguaggio di programmazione può fare.
HTML è un linguaggio a marcatori usato per strutturare documenti.
Per dirla in maniera ancora più tecnica, HTML non è un linguaggio Turing completo, ciò significa che non ha lo stesso potere computazionale di una macchina di Turing universale. Se sei interessato a questo concetto ti consiglio la visione di questo video a riguardo.
Caricamento...
Diventiamo amici di penna? ✒️
Iscriviti alla newsletter per ricevere una mail ogni paio di settimane con le ultime novità, gli ultimi approfondimenti e gli ultimi corsi gratuiti puubblicati. Ogni tanto potrei scrivere qualcosa di commerciale, ma solo se mi autorizzi, altrimenti non ti disturberò oltre.
Se non ti piace la newsletter ti ricordo la community su Discord, dove puoi chiedere aiuto, fare domande e condividere le tue esperienze (ma soprattutto scambiare due meme con me). Ti aspetto!