Nell’introduzione ai VCS abbiamo già parlato dei DVCS o Distributed Version Control System. Andiamo un pochino più nel dettaglio capendoli un attimino meglio.
Cosa sono i Sistemi di versionamento distribuiti
Prima però un piccolo ripasso. Quando i CVCS risultavano fallaci dal punto di vista della sicurezza che il lavoro non andasse in fumo a causa di malfunzionamenti sul server sono stati creati i DVCS, i quali sono un insieme delle LVCS e CVCS, dove ogni membro del team ha una copia locale completa della repository. Per repository si intende il database di versionamento presente sul server. Questo permetterà di eseguire commit, creare branch e unificarle e quando sarà opportuno la repository potrà essere aggiornata, così che tutti gli altri membri del team possano a loro volta aggiornare la propria codebase con la versione più recente.
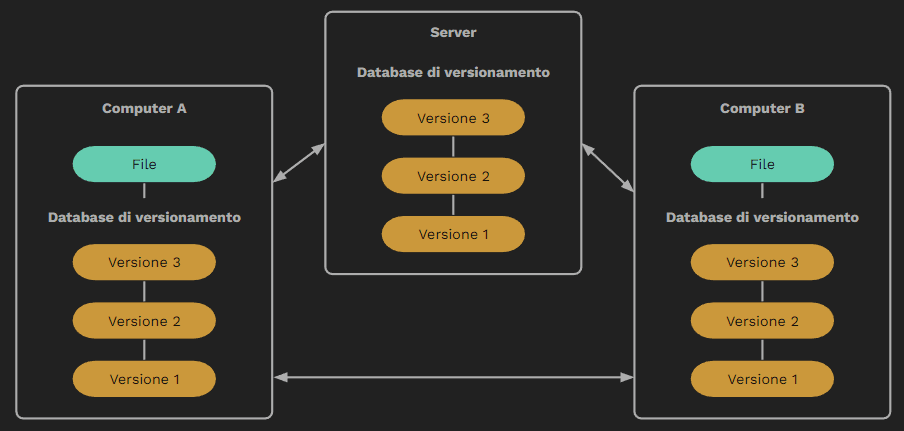
Una peculiarità delle DVCS piú performanti è che il server non archivia i file di ogni ramo, ha solo bisogno delle differenze tra ogni commit.
Per commit si intende quell’insieme di modifiche che si è deciso di salvare sul database di versionamento.
Git non è l’unico DVCS disponibile
Git non è l’unica soluzione sul mercato, è solo la più popolare. La sua popolarità però è dovuta alle sue caratteristiche che non lo rendono unico, ma semplicemente più performante.
Git ha un market share superiore all’85%, ma questo non vuol dire che le altre soluzioni siano in completo disuso. Mercurial, Bazaar e Subsystem (questo però è una CVCS) per quanto abbiano fette di mercato decisamente molto più piccole, esistono e potrebbe capitarvi di sentirle.
In particolare voglio concentrarmi sul primo che ho nominato perché Mercurial ha la peculiarità rispetto a Git o Bazaar di avere una curva di apprendimento molto più rapida ed è considerato in generale come una soluzione ideale per chi inizia. Vediamo un pochino quindi le differenze con Git. Git e Mercurial: due DVCS a confronto Inutile sottolineare che entrambe sono DVCS, se vogliamo flexare a favore di Git (in fondo il protagonista è lui) come DVCS è praticamente uno standard.
Da qui cerchiamo di mantenere quanto più possibile un tono imparziale.
Mercurial è un DVCS perfetto per chi si approccia per la prima volta agli strumenti di versionamento. Molti concetti presenti in altri DVCS qui non ci sono. Che sotto un certo punto di vista è un bene perché evita astrazioni superflue o concetti decisamente troppo complessi.
Come accennato prima la curva di apprendimento è molto veloce. Purtroppo però una nota a sfavore di Mercurial è sul come gestisce le branch (le ramificazioni). Il modello sulla quale si basa è decisamente confusionario.
Nello specifico le ramificazioni fanno riferimento ad una successione di changesets (csets) consecutivi.
I csets fanno riferimento ad un set di modifiche completo fatto ad un file in una repository.
Le branch vengono incorporate nelle commit, così da archiviarle per sempre. Le ramificazioni quindi non potranno essere rimosse perché altrimenti altererebbero la cronologia. I segnalibri permettono di accedere a specifiche commit, simulando il comportamento standard di Git.
Bisogna prestare particolare attenzione a non inviare il codice al ramo sbagliato, soprattutto in caso di nomenclatura poco chiara.
In Mercurial non esiste indice o staging area. Le modifiche vengono salvate così come sono nella directory di lavoro. Su quest’ultimo aspetto, come dicevo prima, potrebbe anche suonare come un bene. Se si vuole comunque avere qualcosa di simile alla staging area si può intervenire con delle estensioni come DirState o Mercurial Queues.
Git, dall’altra parte, invece, è decisamente più indicato per gli sviluppatori esperti (bravo Manuel che stai facendo un corso per principianti) essendo anche più complicato e con più comandi rispetto a Mercurial.
Il modello di branching però è tutto un altro pianeta rispetto ad altri DVCS (non solo Mercurial).
Git ha, a detta di molti, un modello di branching molto efficace. Le ramificazioni fanno riferimento solo ad alcune commit, rendendo l’intero sistema leggero e potente.
Le branch possono essere create, eliminate e cambiate in qualsiasi momento senza influenzare la cronologia.
Inoltre, Git supporta la staging area. Un’area dov’è possibile aggiungere i file che saranno oggetto della commit successiva.
A questo punto il discorso è chiaro e nonostante Git sia per esperti, noi lo affrontiamo comunque a testa alta, perché in fondo, tutti gli esperti sono stati dei principianti.
Andiamo quindi a conoscere più a fondo il nostro protagonista, Git.
Git e Mercurial: due DVCS a confronto
Inutile sottolineare che entrambe sono DVCS, se vogliamo flexare a favore di Git (in fondo il protagonista è lui) come DVCS è praticamente uno standard.
Da qui cerchiamo di mantenere quanto più possibile un tono imparziale.
Mercurial è un DVCS perfetto per chi si approccia per la prima volta agli strumenti di versionamento. Molti concetti presenti in altri DVCS qui non ci sono. Che sotto un certo punto di vista è un bene perché evita astrazioni superflue o concetti decisamente troppo complessi.
Come accennato prima la curva di apprendimento è molto veloce. Purtroppo però una nota a sfavore di Mercurial è sul come gestisce le branch (le ramificazioni). Il modello sulla quale si basa è decisamente confusionario.
Nello specifico le ramificazioni fanno riferimento ad una successione di changesets (csets) consecutivi.
I csets fanno riferimento ad un set di modifiche completo fatto ad un file in una repository.
Le branch vengono incorporate nelle commit, così da archiviarle per sempre. Le ramificazioni quindi non potranno essere rimosse perché altrimenti altererebbero la cronologia. I segnalibri permettono di accedere a specifiche commit, simulando il comportamento standard di Git.
Bisogna prestare particolare attenzione a non inviare il codice al ramo sbagliato, soprattutto in caso di nomenclatura poco chiara.
In Mercurial non esiste indice o staging area. Le modifiche vengono salvate così come sono nella directory di lavoro. Su quest’ultimo aspetto, come dicevo prima, potrebbe anche suonare come un bene. Se si vuole comunque avere qualcosa di simile alla staging area si può intervenire con delle estensioni come DirState o Mercurial Queues.
Git, dall’altra parte, invece, è decisamente più indicato per gli sviluppatori esperti (bravo Manuel che stai facendo un corso per principianti) essendo anche più complicato e con più comandi rispetto a Mercurial.
Il modello di branching però è tutto un altro pianeta rispetto ad altri DVCS (non solo Mercurial).
Git ha, a detta di molti, un modello di branching molto efficace. Le ramificazioni fanno riferimento solo ad alcune commit, rendendo l’intero sistema leggero e potente.
Le branch possono essere create, eliminate e cambiate in qualsiasi momento senza influenzare la cronologia.
Inoltre, Git supporta la staging area. Un’area dov’è possibile aggiungere i file che saranno oggetto della commit successiva.
A questo punto il discorso è chiaro e nonostante Git sia per esperti, noi lo affrontiamo comunque a testa alta, perché in fondo, tutti gli esperti sono stati dei principianti.
Andiamo quindi a conoscere più a fondo il nostro protagonista, Git.
Cos’è Git
Git è un progetto open source, originariamente sviluppato nel 2005 da Linus Torvalds, il famoso creatore del kernel Linux.
Moltissimi progetti si basano su Git per il controllo di versione, inclusi progetti commerciali e open source.
Git, come dicevo qualche paragrafo più in su, deve la sua popolarità alle performance che lo caratterizzano. Questo perché viene pensato e sviluppato con le performance in mente. Questo include la gestione delle commit, ramificazioni, unioni e confronti.
Git lavora principalmente in tre aree
Le vedremo di continuo una volta passati alla parte pratica, ma in linea di massima le aree di Git sono tre e sono:
- Working Directory: il codice sorgente nella sua versione più recente (checkout) risiede qui. Corrisponde alla cartella nel nostro computer, quella che apriamo nel nostro editor per lavorare.
- Staging Area: è un’area fittizia, non esiste veramente, qui è dove i file vengono contrassegnati per essere inclusi nella commit successiva.
- Git Directory: i file sono salvati nel database di versionamento
Gli stati dei file
I file presenti nella nostra working directory possono cambiare di stato, Git infatti ce li contrassegnerà in modo differente in base a delle specifiche situazioni, come:
- Senza traccia (Untracked): il file è presente nella directory di lavoro, ma non è stato mai oggetti di commit o inserito in staging area. Git ci avvisa quindi che il file non essendo tracciato non sarà possibile vederne la cronologia.
- Senza storia (Staged): il file è stato aggiunto per la prima volta alla staging area, questo fa sì che Git gli assegni un indice. Il file è quindi pronto per essere inserito nella commit successiva.
- Modificato (Modified): Il file è stato precedentemente salvato nella git directory e ciò che è presente nella working directory non corrisponde.
- Committed: Il file è stato salvato nella git directory e quello presente in working directory è identico.
Come sviluppatori potremmo avere la necessità di ignorare alcuni file, anzi è estremamente comune che alcuni file o intere directory debbano essere ignorate, abbiamo la possibilità di farlo e lo vedremo meglio più avanti.
Il workflow di base
Se cercate online ci sono millemila modi di gestire il proprio workflow con Git, ma quello più semplice e basilare è questo:
- Modifica dei file nella Working Directory
- Contrassegna dei file da includere nella successiva commit, inserendoli nella Staging Area
- Salvataggio dei file nell’area di stage nella Git Directory.
Poi si può pontificare fino allo stremo sulle varie sfumature di questi tre passaggi, ma per ora cerchiamo di mantenere ancora le cose basilari.
Caricamento...
Diventiamo amici di penna? ✒️
Iscriviti alla newsletter per ricevere una mail ogni paio di settimane con le ultime novità, gli ultimi approfondimenti e gli ultimi corsi gratuiti puubblicati. Ogni tanto potrei scrivere qualcosa di commerciale, ma solo se mi autorizzi, altrimenti non ti disturberò oltre.
Se non ti piace la newsletter ti ricordo la community su Discord, dove puoi chiedere aiuto, fare domande e condividere le tue esperienze (ma soprattutto scambiare due meme con me). Ti aspetto!